Comparing AWS EFA and On-Prem Networking for AI Workloads
AWS EFA vs InfiniBand & RoCE: Learning About AI Networking
Recently, whilst doing some casual reading on semianalysis.com, I came across an intriguing paragraph that sparked my curiosity about networking technologies for AI workloads in AWS:
As predicted two years ago, key to Amazon’s underperformance is the use of custom networking fabric EFA. AWS’s success with ENA on the frontend network has not yet translated to EFA on the backend. EFA still lags behind other networking options on performance: NVIDIA’s InfiniBand and Spectrum-X, as well as RoCEv2 options from Cisco, Arista, and Juniper.
This prompted me to dive deeper into understanding Elastic Fabric Adapter (EFA) and how this technology compares against other networking solutions commonly used in High Performance Computing (HPC) applications, such as RDMA over Converged Ethernet version 2 (RoCEv2) and InfiniBand. Whilst I’ve encountered EFA in previous work engagements, I haven’t thoroughly examined its technical characteristics or performance trade-offs.
Understanding AWS Elastic Fabric Adapter (EFA)
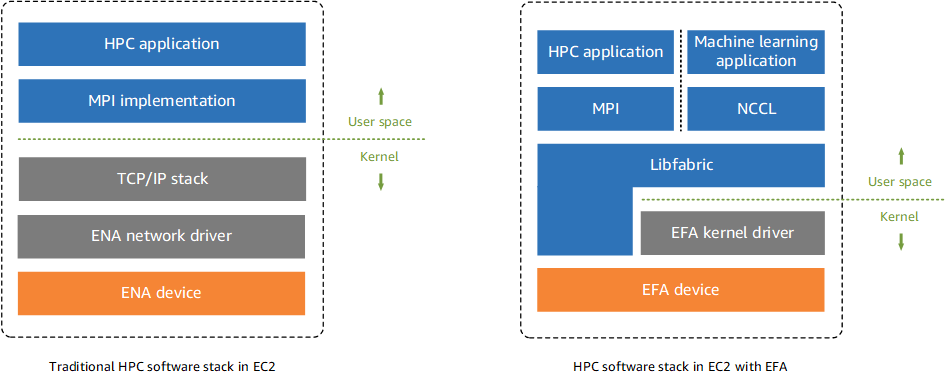
AWS designed EFA as a high-performance interconnect specifically for EC2 instances running Message Passing Interface (MPI) or NVIDIA Collective Communications Library (NCCL) workloads. The technology promises to deliver “lower and more consistent latency and higher throughput than TCP” on the AWS fabric, achieved through kernel-bypass capabilities and a custom transport protocol called Scalable Reliable Datagram (SRD).
What particularly interests me about EFA’s approach is how AWS engineers have designed the system to avoid Priority Flow Control (PFC) - a mechanism that traditional high-performance networks rely upon. EFA provides lower and more consistent latency and higher throughput than the TCP transport traditionally used in cloud-based HPC systems. Instead of requiring PFC at hyperscale (which AWS engineers point out leads to head-of-line blocking and deadlocks), EFA’s SRD transport sends packets out-of-order across multiple paths and reorders them in software, helping to mitigate congestion effects on tail latency.
When attached to a Nitro-based EC2 instance, EFA is a network interface for Amazon EC2 instances that enables customers to run applications requiring high levels of inter-node communications at scale on AWS. The adapter provides an operating system (OS)-bypass, Remote Direct Memory Access (RDMA)-capable interface that integrates with Libfabric, NCCL, and MPI libraries. This design allows MPI or NCCL to communicate directly with the network hardware, avoiding kernel overhead and enabling what AWS describes as “low-latency, low-jitter” inter-instance communication.

Earlier EFA generations operated at 100 Gbps per interface, whilst newer Nitro cards have doubled that capacity. P6e-GB200 UltraServers and P6-B200 instances provide 400 GB per second per GPU of EFAv4 networking for a total of 28.8 Tbps per P6e-GB200 UltraServer and 3.2 Tbps per P6-B200 instance. These UltraServers also support NVIDIA GPUDirect RDMA, enabling direct GPU memory sharing between instances over EFA.

Examining InfiniBand and RoCE Technologies
InfiniBand was purpose-built as an HPC interconnect from the ground up. Most of the fastest supercomputers utilise InfiniBand technology, with measurements for latency as low as 600ns end-to-end. Modern High Data Rate (HDR) and Next Data Rate (NDR) InfiniBand networks offer impressive capabilities: HDR InfiniBand, which has an ultra-low latency (just above 100 nanoseconds) and high speed (up to 200 Gbps), whilst InfiniBand excels in latency, often achieving sub-microsecond delays, critical for AI training where GPUs or TPUs exchange massive datasets.
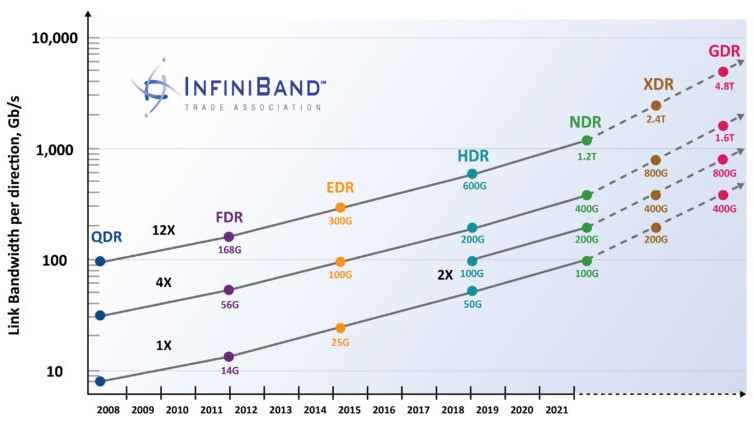
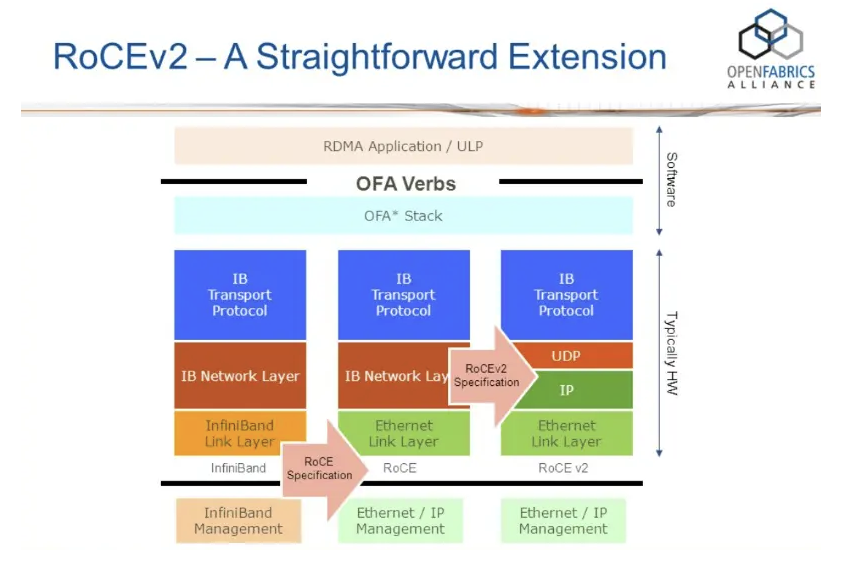
RDMA over Converged Ethernet (RoCE) version 2, or RoCEv2, essentially brings the same RDMA primitives over standard Ethernet infrastructure. This technology typically operates at 100 Gbps and beyond, provided that switches and Network Interface Cards (NICs) support the capability. Under ideal conditions, Ethernet latencies range from around 20 to 80 microseconds, InfiniBand clocks in at 3 to 5 microseconds, though these figures require careful PFC tuning to approach InfiniBand’s reliability and latency characteristics.
Exploring Performance and Protocol Differences
InfiniBand and RoCE use ordered delivery mechanisms, meaning a lost packet holds up subsequent packets until recovery occurs. Both technologies also offer one-sided RDMA verbs, allowing applications to directly read or write remote memory without involving the remote CPU.
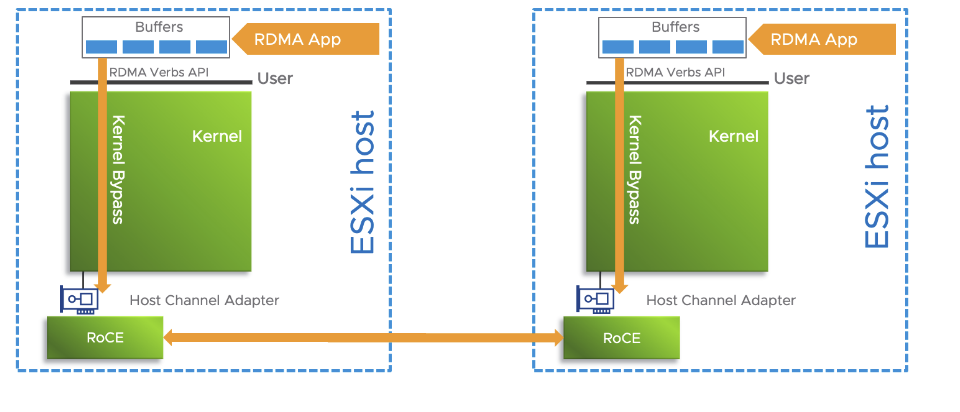
AWS’s SRD on EFA takes a different approach, providing reliable but unordered delivery. The API accessible via Libfabric, primarily offers two-sided send/receive semantics by default. This design choice has implications: workloads that rely on InfiniBand’s one-sided RDMA capabilities (such as shared-memory databases or one-sided MPI operations) may require redesign when migrating to EFA.
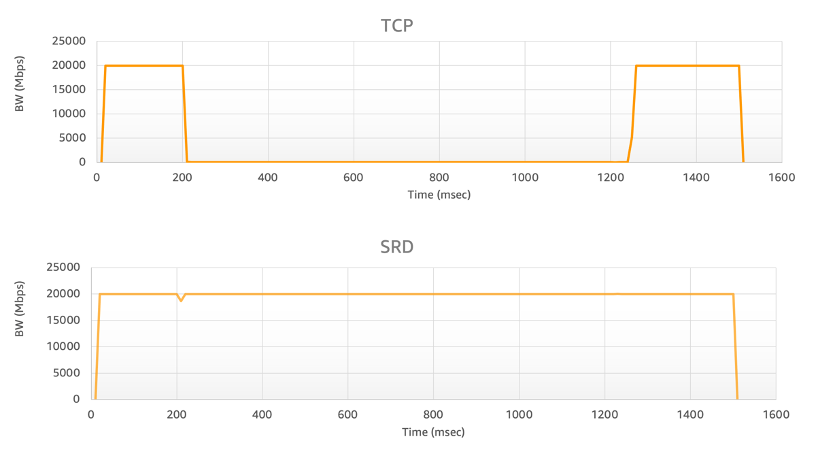
From a performance perspective, it looks like EFA generally lags behind InfiniBand and RoCE in raw performance metrics, particularly for small message sizes. Studies indicate that RDMA’s latency can be approximately 10–20 times lower than EFA’s SRD for typical MPI message sizes. For context, whilst RDMA might achieve around 1 microsecond round-trip on small packets, EFA might require approximately 10 microseconds (though this remains substantially better than traditional TCP/IP).
The performance for large messages has increased by 10% and the performance for small messages has increased by 50% with EFA improvements, but the fundamental performance gap remains. Practically, a single CPU thread using EFA might achieve perhaps 2 million small messages per second per NIC core, whereas InfiniBand easily exceeds 20–30 million messages per second on similar hardware.
For large data transfers, both networking fabrics can approach comparable line rates. Both InfiniBand and EFA can reach near 100–200 Gbps in bulk transfers once sufficient messages are in flight. However, without many outstanding messages, EFA’s higher latency becomes a bottleneck, as RDMA’s lower latency enables more effective pipelining without requiring deep queues.
Summary and Practical Considerations
AWS EFA represents a powerful cloud RDMA solution, but the technology operates with meaningful trade-offs compared to InfiniBand or RoCE environments found in dedicated HPC clusters.
The performance implications for HPC workloads are quite tangible: EFA’s higher latencies (5-10 microseconds versus InfiniBand’s sub-microsecond performance) and unordered delivery mechanisms create measurable overhead in tightly-coupled parallel applications. For computational workloads requiring frequent synchronisation - such as iterative solvers, particle simulations, or large-scale numerical computations - this networking choice directly impacts parallel efficiency and scalability.
The architectural differences extend beyond raw performance. InfiniBand and RoCEv2 networks provide ordered delivery and hardware one-sided RDMA capabilities that enable efficient implementation of parallel algorithms with fine-grained communication patterns. EFA’s software-based packet reordering introduces additional overhead, particularly problematic for applications that depend on precise timing coordination or synchronous communication across distributed processes.
For organisations choosing between networking approaches for HPC deployments, the decision hinges on application requirements and computational patterns. Traditional HPC centres with InfiniBand or RoCEv2 infrastructure may find their parallel applications perform more efficiently on these established networks, particularly for communication-intensive workloads. AWS customers benefit from EFA’s cloud-native integration and on-demand scalability, though must design applications to accommodate the networking characteristics.
The practical reality is that many HPC workloads can be adapted to work effectively with EFA’s latency profile through careful algorithm design - implementing asynchronous communication patterns, increasing computational granularity, and overlapping communication with computation. However, for applications where communication represents the critical bottleneck in parallel performance, understanding these networking fundamentals becomes essential for making informed infrastructure decisions.
Key Takeaways:
- EFA offers cloud-native high-performance networking with kernel bypass and congestion control
- InfiniBand provides lower latencies (sub-microsecond) but requires dedicated infrastructure
- RoCEv2 bridges RDMA capabilities over Ethernet but needs careful PFC configuration
- For HPC applications, network choice depends on communication patterns and scalability requirements
- EFA continues improving with each generation, though a performance gap with InfiniBand persists