AI Data Centre Networking: Takeaways and Beyond
Introduction
After listening to the insightful Heavy Networking podcast episode 782, I felt compelled to delve deeper into the intricacies of AI data centre networking. The episode shed light on the challenges and solutions in automating networks for AI workloads, prompting me to explore the architectural distinctions and considerations in AI cluster networks.
What struck me most was how fundamentally different AI training networks are from traditional data centre infrastructure. Having spent years working with conventional server deployments, I’ve come to appreciate that AI workloads don’t just require more bandwidth—they demand an entirely different approach to network design, from physical topology to congestion control mechanisms.
Let me break down the core networking considerations for AI training workloads as I understand them.
The Fundamental Shift: Why Traditional Networks Fall Short
When I first encountered AI training requirements, I naively assumed we could simply scale up existing network designs. More servers mean more switches, right? This thinking proved woefully inadequate once I understood what actually happens during distributed AI training.
Traditional data centre workloads—web servers, databases, microservices—generate what network engineers call “mice flows.” These are small, short-lived connections with relatively modest bandwidth requirements. A web server might handle thousands of concurrent connections, but each individual request transfers relatively little data. Network congestion causes slight delays, users wait a moment longer for pages to load, but the world doesn’t end.
AI training generates “elephant flows”—massive, sustained data transfers between GPUs that must remain perfectly synchronised. When training a large language model across hundreds of GPUs, these processors constantly share gradients, weights, and intermediate results. Any disruption—a dropped packet, momentary congestion, even microseconds of additional latency—can cause the entire training job to slow down or fail completely.
The economic impact is staggering: when you’re paying millions for GPU time, network inefficiencies directly translate to massive waste.
Front-End vs Back-End AI Cluster Networks
In modern AI training clusters, I’ve learnt that the networking stack is typically divided into two distinct fabrics, each optimised for completely different requirements:
Front-End Networks: The Traditional Side
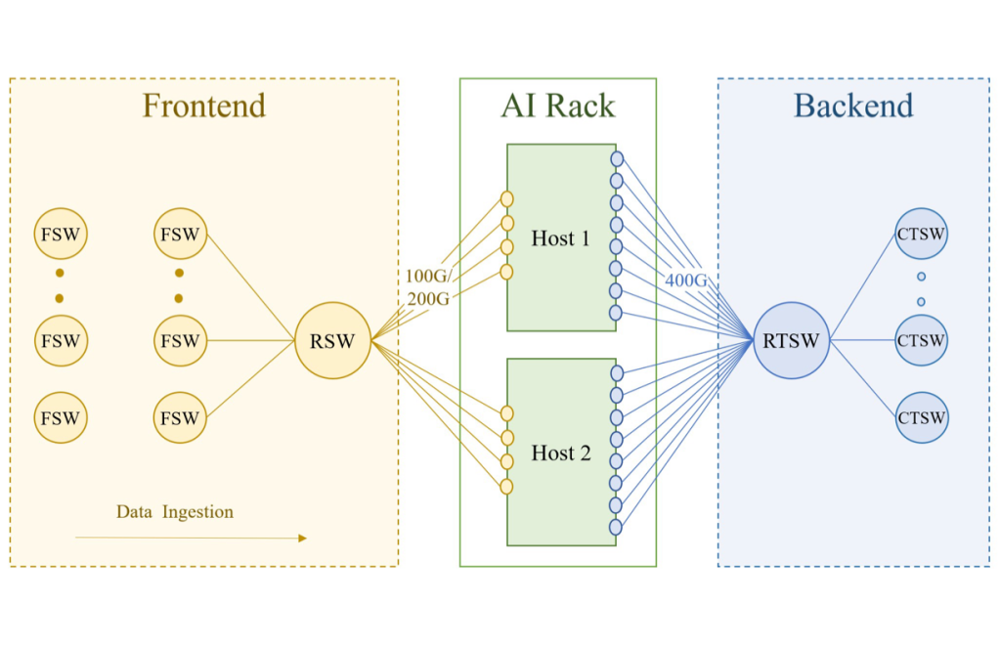
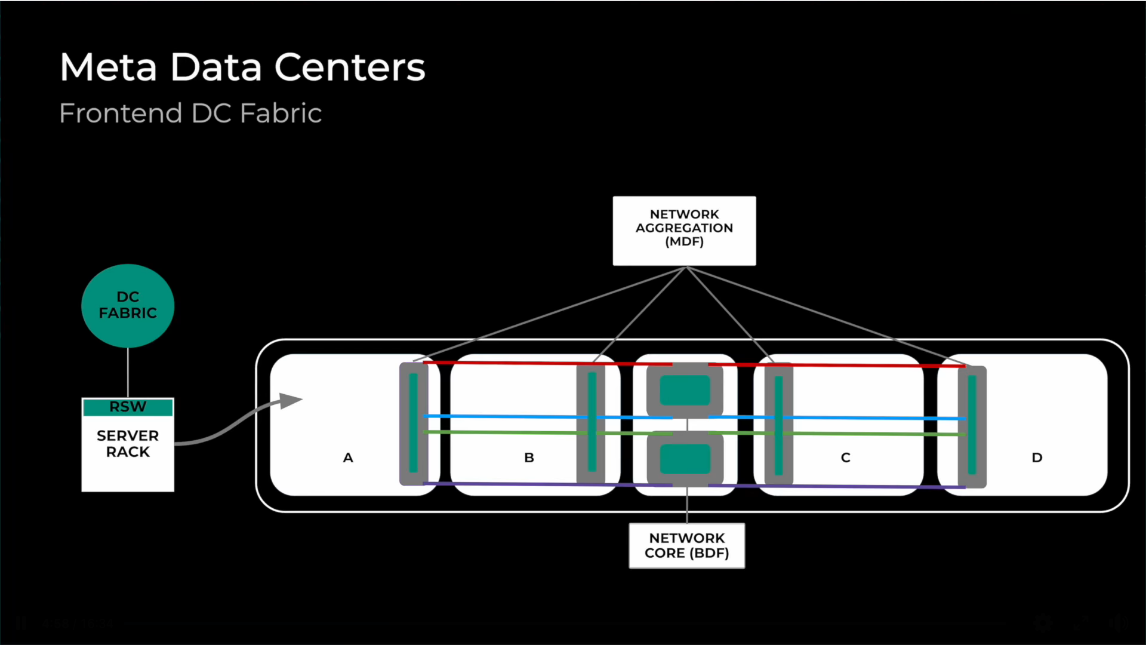
The Front-End (FE) handles what you’d expect from any data centre network: user access, management traffic, and crucially, data ingestion for training jobs. This network looks relatively familiar—traditional Ethernet switches arranged in typical spine-leaf topologies, connecting to storage systems and external networks.
When training a new model, enormous datasets must flow into the cluster through this front-end network. We’re talking about terabytes or petabytes of training data that needs reliable, high-throughput delivery to the compute nodes. However, this traffic is more forgiving than the back-end requirements—if data ingestion slows slightly, training might delay but won’t crash.
Back-End Networks: The High-Performance Beast
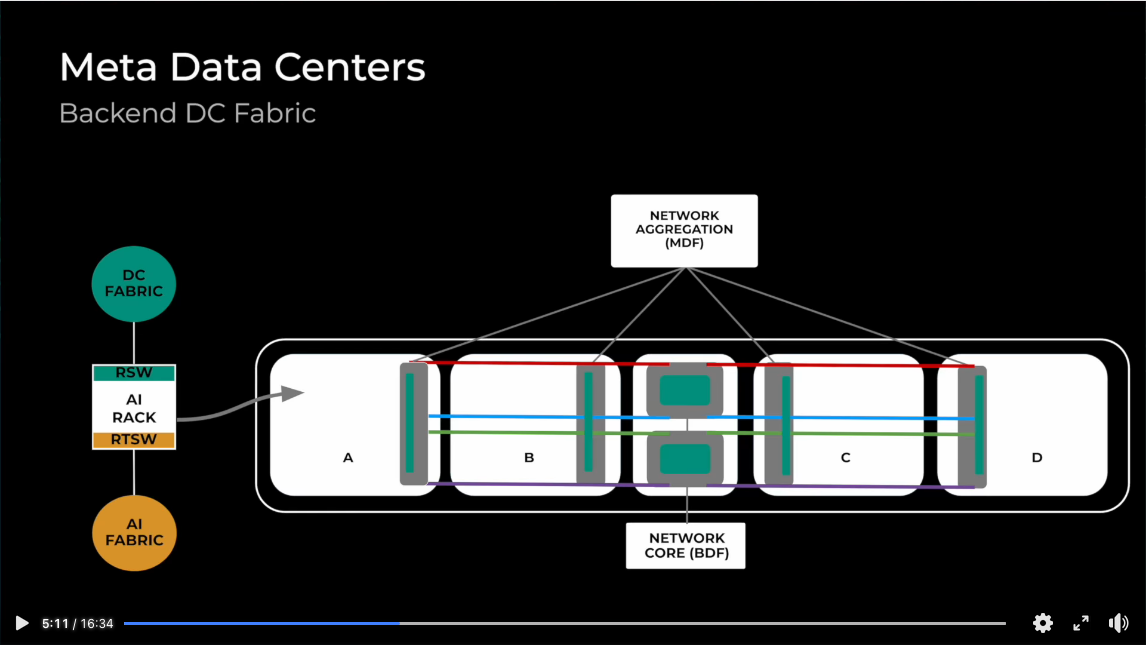
The Back-End (BE) is where the magic happens, and where traditional networking wisdom breaks down completely. This fabric exists for one purpose: enabling GPU-to-GPU communication during training with ultra-low latency and zero packet loss.
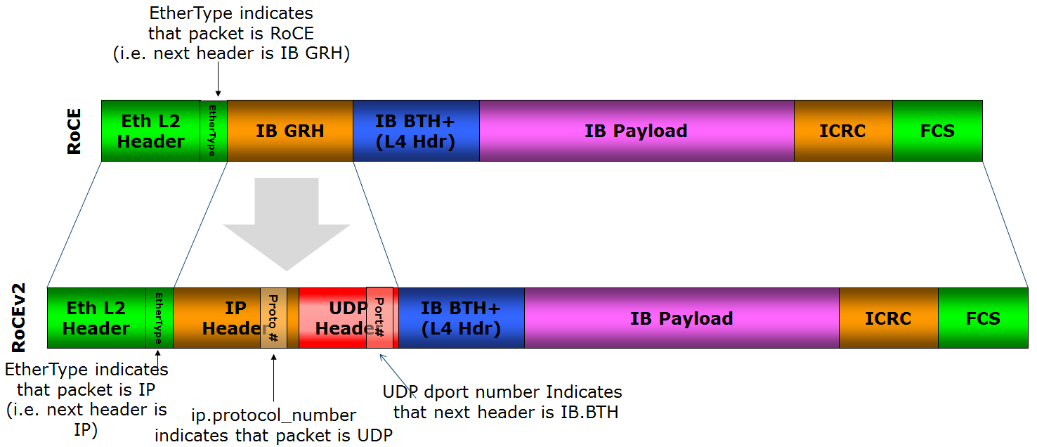
From my research into various implementations, organisations implement dual-homing for each rack, connecting them to both FE and BE networks. The FE utilises conventional 100/200GbE Ethernet, while the BE typically operates on 400GbE+ RoCE or InfiniBand, catering to the high-throughput demands of AI workloads.
The back-end network must deliver three critical characteristics that traditional networks rarely optimise for simultaneously:
Perfect synchronisation: During distributed training, all GPUs must remain in lockstep. When one GPU completes a calculation, it must immediately share results with hundreds or thousands of other GPUs. Any delay causes expensive hardware to sit idle.
Lossless communication: Traditional networks tolerate occasional packet loss—TCP will simply retransmit. In AI training, retransmission destroys the precise timing requirements. The network must guarantee that every packet arrives successfully on the first attempt.
Massive bandwidth: Modern AI models involve billions of parameters that must be continuously shared across the cluster. This requires sustained high-bandwidth communication between all participants, far exceeding typical data centre requirements.
Ethernet vs InfiniBand: The Great Debate
One of the most contentious decisions in AI networking is choosing between Ethernet-based solutions and InfiniBand. Having evaluated both approaches, I’ve found each has compelling advantages:
InfiniBand: The Performance Champion
| Feature | InfiniBand (IB) | Ethernet (RoCEv2) |
|---|---|---|
| Ecosystem | Proprietary (NVIDIA) | Open-standard, multi-vendor |
| Flow Control | Credit-based, in-switch SHARP | PFC, ECN, DCQCN, software pacing |
| Latency | Lower | Slightly higher, closing the gap |
| Usage | HPC clusters | AI training clusters (Meta, AWS, etc.) |
InfiniBand evolved in high-performance computing environments where microsecond latencies matter enormously. It provides native end-to-end flow control, adaptive routing, and hardware-accelerated collective operations. For pure performance, InfiniBand typically wins.
However, InfiniBand’s proprietary nature creates challenges. You’re largely locked into NVIDIA’s ecosystem—switches, NICs, cables, and management tools all come from a single vendor. This can create supply chain risks and limits competitive pricing.
Ethernet: The Pragmatic Choice
RoCEv2 over Ethernet is gaining significant traction in AI environments, and I understand why. While it may not match InfiniBand’s absolute performance, it offers crucial advantages:
Vendor diversity: Multiple suppliers provide compatible equipment, creating competitive pricing and reducing supply chain risks.
Operational familiarity: Most network teams already understand Ethernet, reducing training requirements and operational complexity.
Integration flexibility: Ethernet-based solutions integrate more easily with existing data centre infrastructure.
The performance gap continues narrowing as Ethernet vendors optimise their solutions for AI workloads. Meta’s success with RoCEv2 at massive scale demonstrates that Ethernet can absolutely support world-class AI training when properly implemented.
Port Speeds, Cabling & GPU Interconnects
The physical infrastructure of AI clusters is as critical as the logical design. Here’s what I’ve observed across various implementations:
Network Interface Speeds
400/800GbE links are becoming standard for inter-switch connections, employing QSFP-DD or OSFP modules to handle vast data throughput. In researching, I have come across some deployments pushing to 800GbE as GPU performance continues advancing, though 400GbE remains common for current-generation deployments.
Within racks: Direct Attach Copper (DAC) cables or optical fibres connect servers to leaf switches, ensuring low-latency communication. DAC cables work well for short distances and offer cost advantages, whilst optical connections provide greater reach and electromagnetic isolation.
GPU Connectivity
Modern AI servers typically provide dedicated network connectivity per GPU rather than sharing NICs across multiple processors. This design prevents network bottlenecks from limiting GPU performance.
NICs: RoCE-capable Network Interface Cards, such as NVIDIA’s ConnectX-6/7, are commonly deployed, often providing one 400GbE port per GPU to maximise bandwidth. This represents a significant departure from traditional servers where multiple processors might share network connectivity.
GPU-to-GPU within servers: Inside individual servers, GPUs interconnect via NVLink or NVSwitch, offering bandwidths around 450GB/s per connection. This high-speed internal connectivity enables rapid data exchange between GPUs in the same chassis before involving the network.
Meta’s reference architecture exemplifies this approach, connecting each GPU directly with a 400GbE NIC to achieve high throughput and minimise bottlenecks. This design philosophy—dedicated, high-bandwidth connectivity per compute unit—represents a fundamental shift from traditional server networking.

Congestion Control and Losslessness: The Technical Challenge
Ensuring a lossless network environment is paramount for AI workloads, and this requirement has driven fascinating innovations in congestion control mechanisms. Traditional networks tolerate occasional packet loss because applications can recover, but AI training demands perfection.
Priority Flow Control (PFC)
PFC (IEEE 802.1Qbb) provides lossless Layer 2 behaviour by pausing traffic during congestion. When a switch’s buffers begin filling, it sends pause frames upstream, temporarily halting transmission until congestion clears.
I’ve learnt that PFC implementation requires careful tuning. Overly aggressive pause behaviour can cause head-of-line blocking, where one congested flow stops unrelated traffic. Conversely, insufficient pause control allows buffer overflows and packet loss.
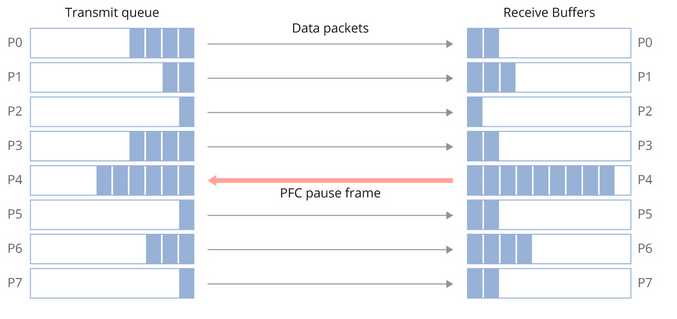
Explicit Congestion Notification
ECN + DCQCN protocols detect and manage congestion at Layer 3, adjusting transmission rates to prevent packet loss rather than simply pausing traffic. This approach provides more granular congestion response whilst maintaining network efficiency.
Interestingly, Meta observed that disabling DCQCN at 400GbE improved performance in their specific environment, relying solely on PFC and receiver-side throttling. This highlights the importance of tailoring congestion control strategies to specific network conditions and workloads rather than applying generic configurations.
Software-Based Flow Control
Software-based pacing: Advanced implementations like Meta’s NCCL modifications implement “clear-to-send” mechanisms, coordinating data transfers at the application level to avoid network congestion entirely. This approach moves intelligence from network hardware into the training software itself.
These application-aware approaches represent the cutting edge of AI networking, where training frameworks actively cooperate with network infrastructure to optimise performance.
ECMP Considerations for AI Elephant Flow Traffic
One of the most revealing aspects of my research was understanding how Equal-Cost Multi-Path (ECMP) routing struggles with AI traffic patterns, a topic highlighted brilliantly in the Heavy Networking podcast.
Traditional ECMP and Ethernet hardware are optimised for high-entropy traffic—many small, diverse flows that can be easily distributed across multiple paths. Network designers assume that hash-based load balancing will naturally distribute traffic because typical applications generate diverse connection patterns.
But AI back-end traffic is fundamentally different. It’s composed of massive, synchronised, low-entropy flows between GPUs. These “elephant flows” often hash to a single ECMP path because the header fields used in the hash (source/destination IP, ports, etc.) don’t vary significantly between related AI communications.
The result? Some links in the ECMP bundle become overutilised whilst others remain underutilised. Worse, if multiple elephant flows hash to the same link, you can completely saturate that path, causing one or more GPUs to idle—directly reducing training performance and wasting costly hardware.
As Alex Saroyan explained in the podcast, these flows don’t adapt well to standard ECMP. Instead, AI networks are adopting adaptive routing techniques. This includes NVIDIA’s proprietary solution where NICs and switches coordinate to send packets along the most available paths—not through ECMP hash buckets but through dynamic, load-aware mechanisms.
Whilst this is sometimes confused with per-packet load balancing, it’s a distinct strategy aimed specifically at maintaining link utilisation and avoiding the congestion hotspots that standard ECMP can create with AI traffic patterns.
Bisection Bandwidth & Oversubscription Strategy
Achieving optimal bisection bandwidth ensures that any server can communicate with any other at full bandwidth—a necessity for efficient AI training that I’ve found requires careful architectural planning.
Non-Blocking Topologies
Enterprise approaches: Vendors like Cisco and Arista promote 1:1 leaf-to-spine topologies, eliminating oversubscription and ensuring consistent performance. These designs work well for moderate-scale deployments where cost-per-port is manageable.
Hyperscaler strategies: Large organisations like Meta may introduce slight oversubscription (e.g., 1.85:1) at higher network tiers to balance cost and performance, mitigating potential issues through intelligent job scheduling and traffic engineering.
The key insight I’ve gained is that AI workloads are less tolerant of performance variability than traditional applications. A web server that occasionally slows down is annoying; an AI training job that sporadically encounters network bottlenecks can fail completely.
Scaling Considerations
Understanding and planning for bisection bandwidth becomes crucial as cluster sizes grow. Small clusters with dozens of GPUs can often achieve true non-blocking connectivity. Clusters with thousands of GPUs require careful traffic engineering and job placement to avoid creating communication hotspots.
Meta’s evolution from simple star topologies to multi-tier Clos fabrics illustrates how bisection bandwidth requirements drive architectural decisions as scale increases.
Topology Evolution: Learning from Scale
My research into various AI deployments reveals a clear evolution pattern as organisations scale their training capabilities:
Small Scale: Star Topologies
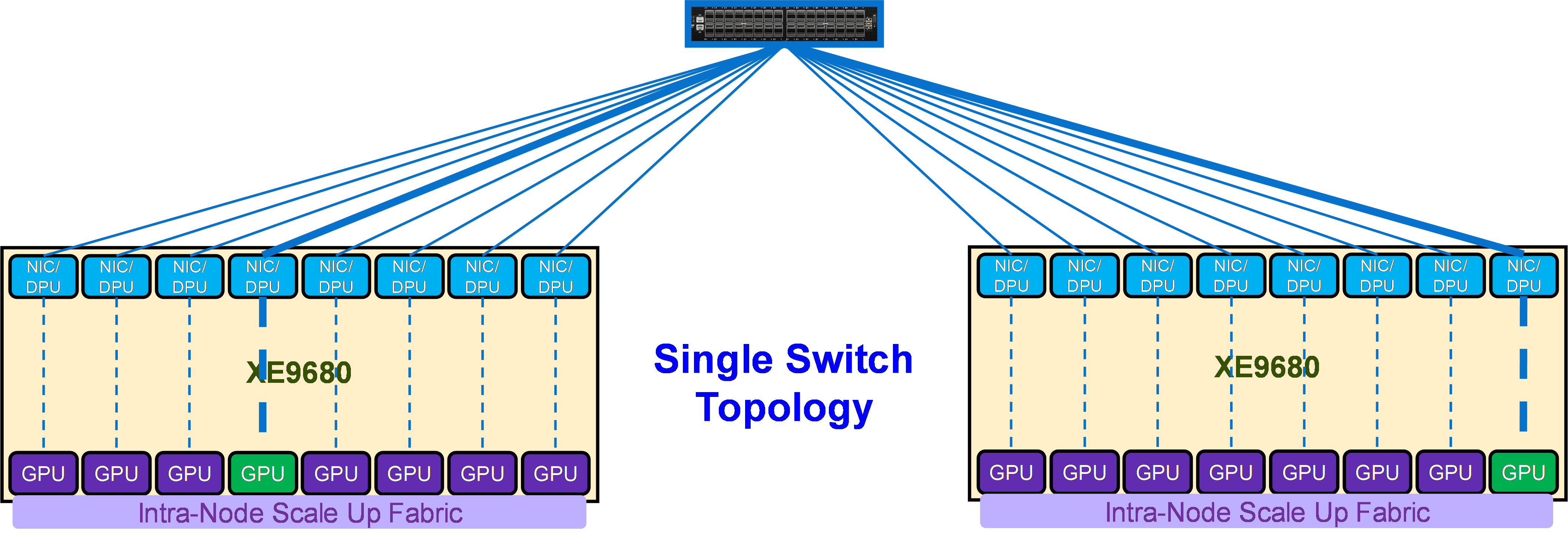
Initial AI deployments often use simple star configurations—all compute nodes connecting to a central high-port-count switch. This approach works well for clusters up to a few hundred GPUs and offers simplicity in management and troubleshooting.
However, star topologies have inherent limitations: single points of failure, limited scalability constrained by switch port counts, and potential bisection bandwidth issues as utilisation increases.
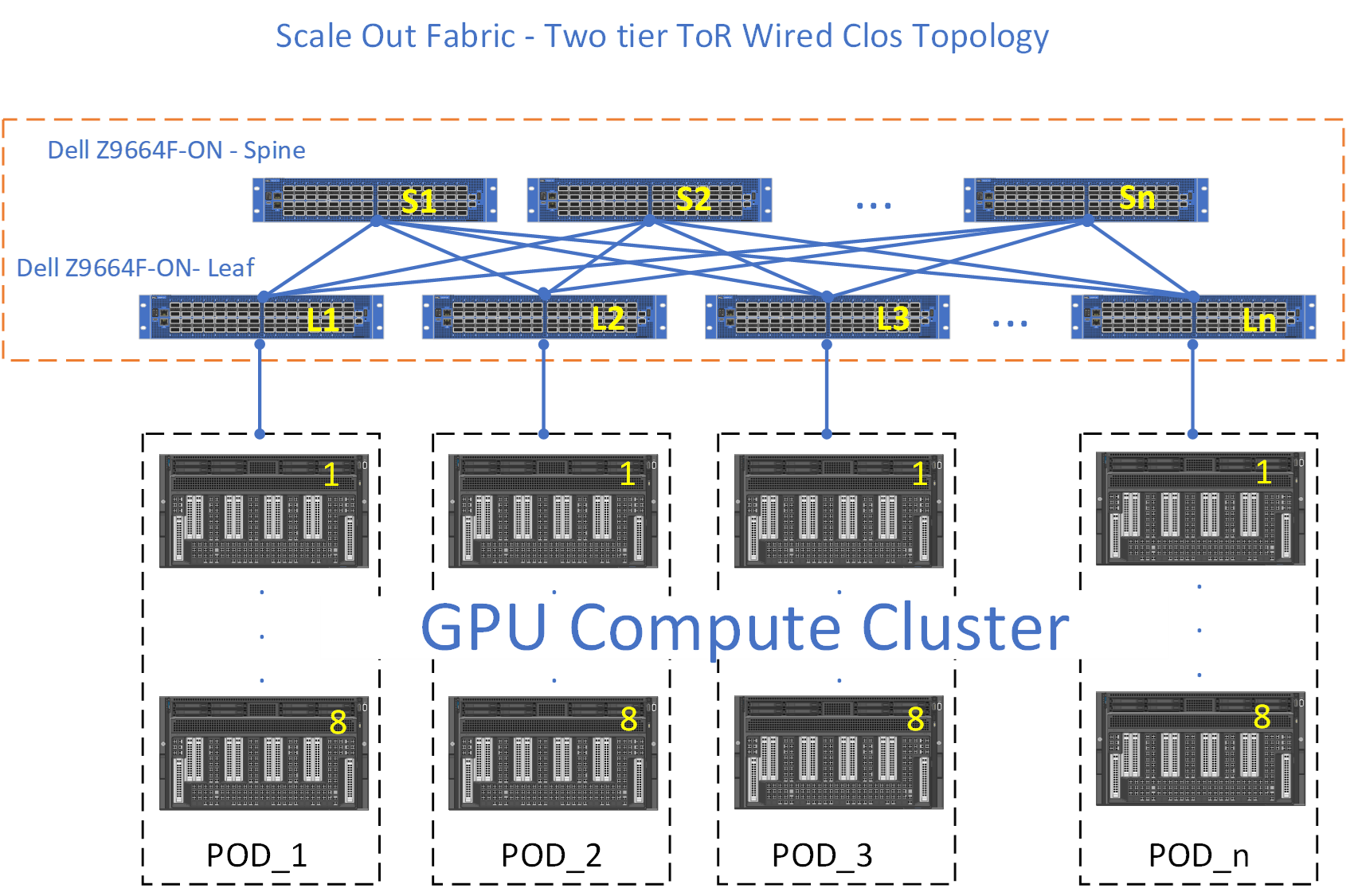
Medium Scale: Two-Tier Clos
As clusters grow beyond star topology limitations, most organisations migrate to two-tier Clos architectures with leaf and spine layers. This design eliminates single points of failure whilst enabling larger cluster sizes.
Leaf switches (often called Rack Training Switches or RTSWs) reside within compute racks and connect directly to GPUs. Spine switches (Cluster Training Switches or CTSWs) provide interconnectivity between leaf switches using high-speed optical links.
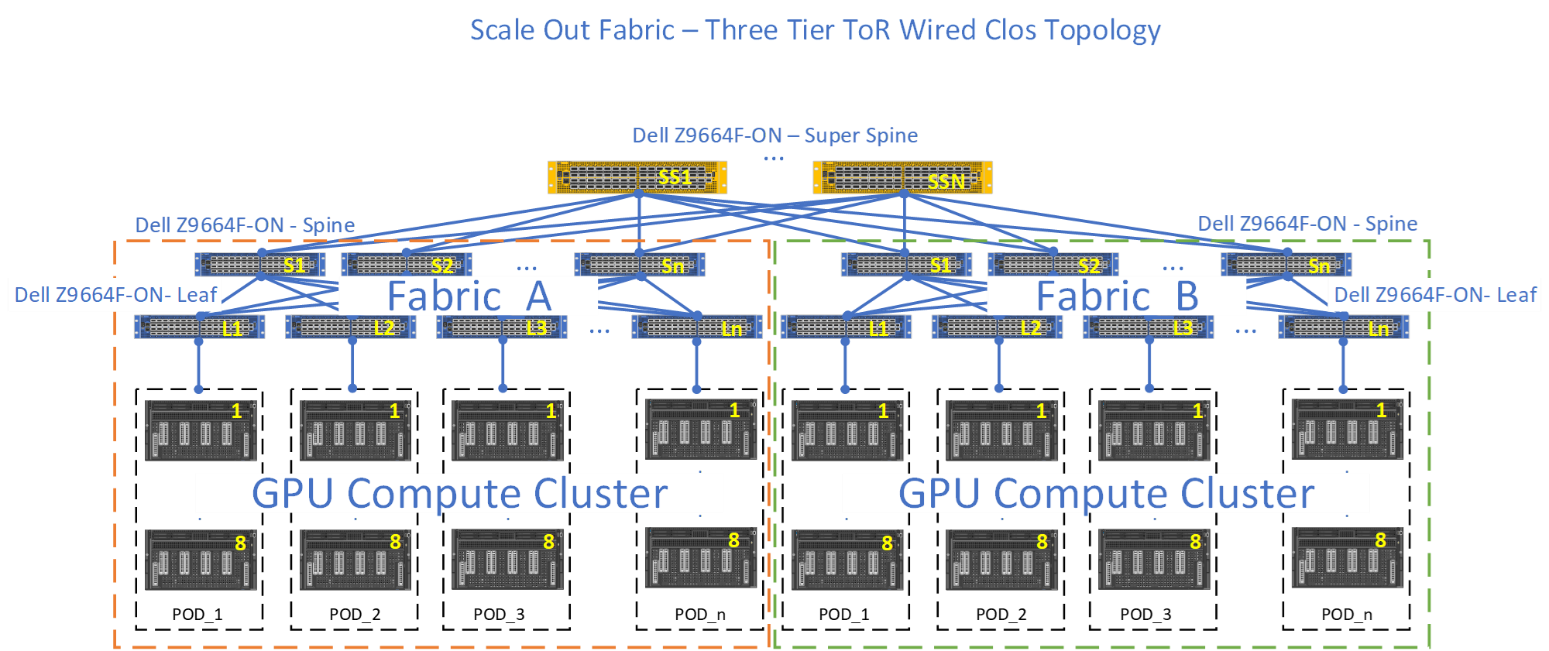
Large Scale: Multi-Zone Architectures
Hyperscale deployments require interconnecting multiple Clos fabrics to create training clusters exceeding 10,000 GPUs. These architectures introduce additional complexity but enable unprecedented computational scale.
The key lesson I’ve drawn from these evolution patterns is that AI networking architecture must be designed for growth from the beginning. The performance and cost penalties of major architectural changes are enormous when dealing with expensive GPU infrastructure.
Automation and Observability: Managing Complexity
The complexity of AI data centres necessitates robust automation and observability tools that go far beyond traditional network management approaches.
Declarative Management
Infrastructure as Code: Platforms like Netris, Juniper Apstra, and Arista CloudVision enable automated deployment and management of lossless fabrics, reducing manual configuration errors that can be catastrophic in AI environments.
I’ve found that traditional CLI-based network configuration becomes unmanageable at AI scales. The number of parameters requiring precise coordination—RDMA settings, buffer configurations, congestion control parameters—makes manual management practically impossible.
Advanced Observability
Telemetry integration: Modern AI networks integrate detailed telemetry with job metadata, allowing comprehensive monitoring that correlates network performance with training job effectiveness.
Real-time diagnostics: Advanced capabilities such as RDMA-aware load balancing, adaptive routing, and real-time diagnostics (e.g., Arista UNO) enhance network responsiveness and reliability.
Streaming telemetry: Provides granular insights into network behaviour, enabling proactive management of congestion and other anomalies before they impact training jobs.
The critical insight is that AI network observability must extend beyond traditional metrics like link utilisation and packet loss. Understanding how network behaviour affects training job performance requires correlation between network telemetry and application-level metrics.
Design by Scale: Enterprise vs Hyperscale Approaches
The scale of deployment significantly influences design choices, and I’ve observed distinct patterns between different organisational scales:
| Cluster Size | Enterprise | Hyperscale |
|---|---|---|
| Typical GPUs | Dozens to hundreds | Thousands to 100K+ |
| Networking | Off-the-shelf Ethernet/RoCE, some oversub | Custom Clos topologies, 400G+/800G+ ports |
| Scheduling | Standard tools (Slurm, Kubeflow) | Custom software with topology awareness |
| Automation | Reference architectures | Full infra-as-code with observability |
Enterprise Considerations
Smaller organisations often prioritise standardised solutions that balance performance with operational simplicity. Some level of oversubscription may be acceptable if job scheduling can work around potential bottlenecks.
Reference architectures from vendors provide valuable starting points, though they require careful adaptation to specific workload patterns and growth plans.
Hyperscale Requirements
Large-scale deployments demand custom solutions optimised for specific requirements. The investment in custom networking, software, and operational tooling becomes justifiable at sufficient scale.
Hyperscalers often develop proprietary solutions for job scheduling, network management, and performance optimisation because off-the-shelf tools cannot accommodate their specific requirements and scale.
Power and Cooling: The Hidden Network Challenge
One aspect that initially surprised me is how AI networking decisions are constrained by power and cooling requirements. GPU racks consume nearly twice the power of traditional servers, and network switches supporting 400GbE+ interfaces also demand significantly more power.
Meta’s experience illustrates this challenge: their latest GPU generation required reducing the maximum number of AI racks per zone to accommodate increased power consumption. This decision directly impacted network topology choices and required additional spine switches to maintain performance.
The lesson is that AI network design cannot be separated from facility infrastructure planning. Network architects must coordinate closely with power and cooling engineers to ensure that networking solutions are actually deployable in real-world environments.
Looking Forward: The Continuing Evolution
What strikes me most about AI networking is how rapidly the requirements continue evolving. Each new GPU generation brings increased performance, power consumption, and interconnectivity demands that drive network architecture changes.
The modular approaches like zone-based architecture—demonstrate the importance of building adaptable infrastructure that can accommodate future requirements without complete redesign. However, the pace of change means that today’s cutting-edge solutions may become tomorrow’s bottlenecks.
Current trends I’m watching include:
- Higher speeds: 800GbE and beyond as GPU performance continues advancing
- Optical innovation: Silicon photonics and co-packaged optics to reduce latency and power consumption
- Adaptive routing: More sophisticated traffic engineering that responds dynamically to workload patterns
- Application integration: Deeper coordination between training frameworks and network infrastructure
Conclusion
Exploring the nuances of AI data centre networking, especially after listening to Heavy Networking podcast with Alex Saroyan and studying implementations like Meta’s, has deepened my appreciation for the intricate balance between performance, scalability, and manageability required for successful AI infrastructure.
The transition from traditional data centre networking to AI-optimised infrastructure represents one of the most significant architectural shifts. It’s not simply about faster links or bigger switches—it requires rethinking fundamental assumptions about traffic patterns, failure modes, and performance requirements.
As AI continues to evolve and models become even more sophisticated, the networking infrastructure supporting them must evolve correspondingly. The organisations that master these networking challenges will have significant competitive advantages in the AI-driven future, whilst those that underestimate the complexity risk expensive failures and missed opportunities.
Sources
- HN782: Netris Meets Your Network Automation Challenges in AI Data Centers (Sponsored)
- Meta: RoCE Network for Distributed AI Training
- Juniper: Networking the AI Data Center
- Arista: AI Networking White Paper
- Extreme Networks: Rise of AI Workloads
- Cisco: Addressing AI/ML Network Challenges
- Meta’s Network Journey to Enable AI | Hany Morsy & Susana Contrera
- Multi-Tenancy & Network Automation for AI Infrastructure Operators Demonstrated with Netris